
The path to applied science co-pilots.
Defining the architecture and data required beyond the LLM.

Language models have gained a huge amount of awareness this year, so the obvious question is can their use overcome the downward trend in productivity in applied science?
At Deep Science Ventures we started testing this just over a year ago with our in-house tool ‘Elman’ using highly custom system prompts optimised for different common tasks in our company creation process. Such as identifying the root cause constraint in a few seconds, finding the key piece of information for a solution deep in one of millions of papers (usually in less than 30 seconds), freedom to operate search live in the flow of your project, or finding a team to take a concept forward.
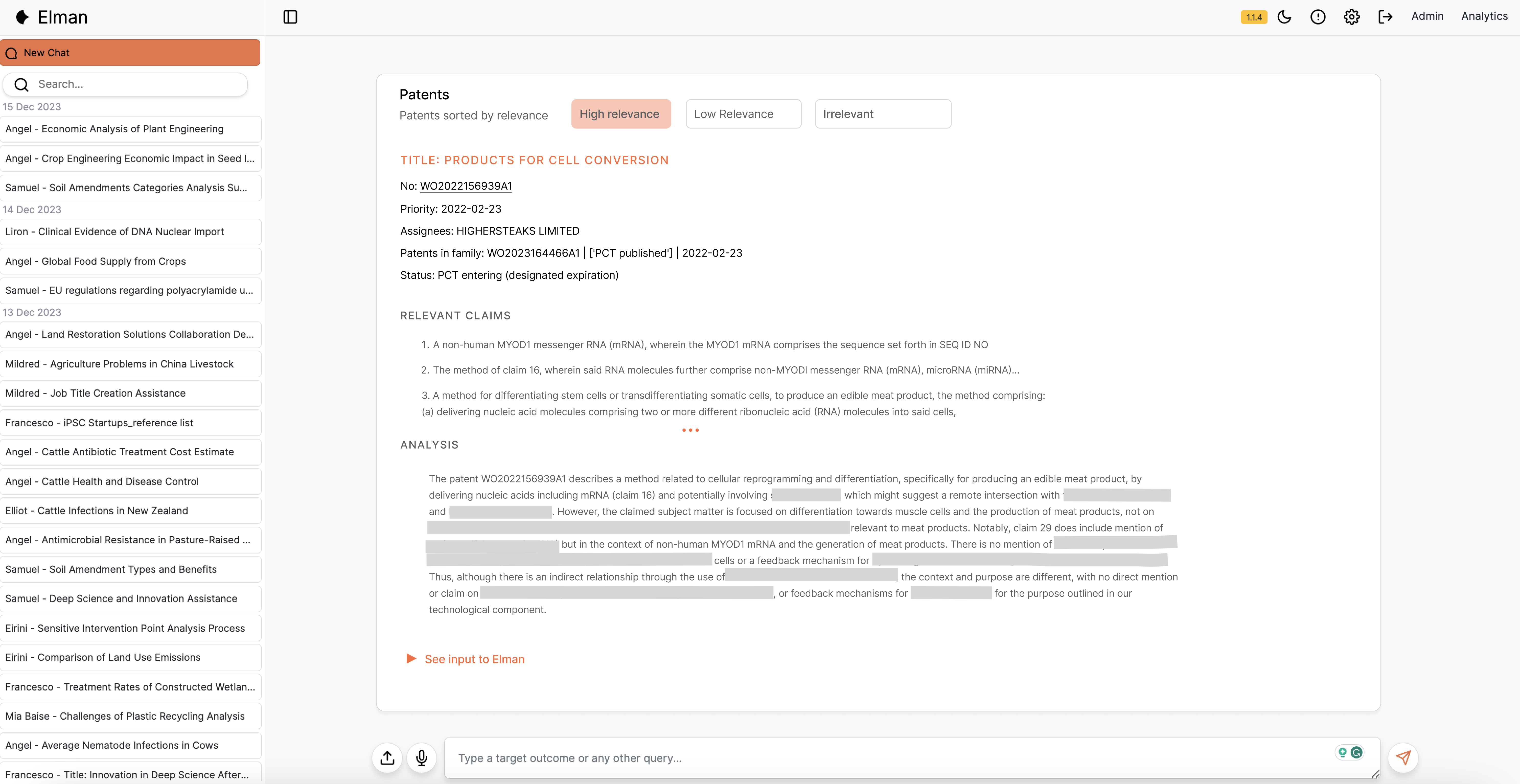
We found in many cases that this can reduce the time to concept from many months to weeks. But this is very dependent on the person using it, i.e., whether they have the right first principles mindset and experience to ask the right questions at the right time. If they do, the system can shape a great answer. The current tools like ours, and external tools like Elicit and Future House, accelerate the scientist, but so far are a long way away from being able to bring everyone up to the level of the greatest innovators.
This limitation, of only accelerating existing skills, is a problem because the skill set required for great applied science (beautifully summarised by Hendrik Karlssob here) is incredibly rare. In our own recruitment data, the required behavioural attributes are present in circa 1 in 500 candidates. The majority are leaders in industry and academia. Clearly, there is a big disconnect between the skills that made leaps in the past and those that are at work right now. This is because these skills are, at best, picked up ad-hoc and, at worst, actively trained out of scientists.
Production line education and the academic publish-or-perish environment are driving a seemingly irreversible trend in declining inventiveness. This is one of the reasons why last year we started a fully accredited College and STEM doctorate, ‘The Venture Science Doctorate’ - a PhD in invention, to ensure that these skills are embedded earlier in the pipeline. Whilst this will address upcoming talent this leaves the question of how to bring up everyone already out there in the same way that Github’s co-pilot has brought up the overall quality and speed of nearly all software developers.
Is there a world in which a virtual applied scientist completely removes the talent bottleneck in startups and industry?
Are co-pilot like leaps in productivity possible in science?
Unfortunately, the answer isn’t to simply train a model on scientific papers and tell it to act like Einstein. Training a model on existing data works well for software development models because developers have written comments next to their code and progress is versioned, and we know that it actually runs. The Meta Galactica debacle showed many of the issues with training on academic data. All we have in science is the end paper, often lacking any reasoning or accuracy.
LLMs on their own aren’t creative
Whilst chatGPT and similar language models often look creative on the surface, take a closer look, and you’ll find that they are rarely productive for this type of work. I.e. There is undoubtedly novelty but it is very hard, maybe impossible, to constrain it in a useful direction with prompting alone. Efforts to get the model to creatively recombine components to solve problems often sound highly novel but completely lack applicability even when very intentionally constrained, as covered in detail on the One Useful Thing blog here.
Despite this, it turns out that language models are actually pretty great at analogies (i.e. joining the dots across areas) with moderate prompting efforts [1,2,3], and we’ve seen fantastic results in-house. This is a key element of creativity (think about how many inventions are inspired by nature for example) but it is not sufficient to work through all of the options.
Stanford actually tried to implement a full stack AI researcher powered just by GPT4. This worked very well for known problems but failed entirely with even the slightest domain shift. It’s becoming very clear that LLMs are extremely sensitive to even slight changes in the domain, for example, changing the names of the rules in a board game which is a major issue as creativity is by definition out of domain.
The challenge is that human creativity comes from a ‘constrained’ search over a wide combinatorial space. A co-pilot-like system will require far more than just a base LLM; it will require leveraging broader computing concepts of optimising exploration of a search space.

The SOTA is at the interface between computational search and LLMs
The OG in the reinforcement learning search space (which is analogous to a search over potential ways to build a new scientific solution) is, of course, Google DeepMind with their AlphaTensor work on generating novel algorithms - even if it was beaten just one week later by two guys and a rule-based method from the history books. This used a pure computational approach in which, in simple terms, the best performing moves in any given situation are more likely to be taken next that situation occurs. This kind of approach works really well when it’s possible to simulate a problem millions of times, but is challenging for environments where we get a very small number of attempts or the ‘moves’ are far more varied than the relatively small number of moves in games and matrix multiplication.
Around a year ago the VOYAGER paper took a stand against reinforcement learning to demonstrate that a process of curriculum learning (working up from small easy tasks to complex compound tasks) can equip an LLM with all it needs to succeed in Minecraft and outperform reinforcement learning. This compositional approach certainly feels much more human. However from the perspective of our goal of novel science we need to recognise that VOYAGER works because there is so much Minecraft strategy data online and in the LLM already, something that isn’t true for the tacit knowledge of applied science.
Finally, just yesterday Google released a follow up to the AlphaGO work, FunSearch, this time adding an LLM into the loop which rewrites a programme that solves a mathematical challenge. Then at each loop, the best performing programmes are picked and mixed under Genetic Algorithm search / optimisation processes. This is also encouraging but again requires both extremely high throughput (millions of tries) and working on code which we know to be very ‘in-domain’ for LLMs.
The next step in automated scientific exploration will need to combine both computational search and embedded human like reasoning.
We need to find methods that work in domains where reasoning data is largely lacking (i.e. not just code / comments in the model), remember LLMs don’t actually reason, they draw a line between similar reasoning data in their training data. The methods also need to tackle the vastly higher complexity of the real world, products and markets vs. the limited number of moves on a game board or in mathematical puzzles. Finally, it needs to work when the number of times we can play the game is highly limited. To address this, Deep Science Ventures is embarking on building a model based on the highest quality applied scientific reasoning.

We thought carefully before embarking on this mission as the history of computer science is full of bitter lessons in time wasted defining expert system rules only for it to plateau and be overtaken by statistical methods (more on this here), so the potential for this feature to emerge in larger models is front of mind. However, given how rare this capability is in the scientific population, one would assume that it’s also rare in the data set, and as such, to me, at least, it seems unlikely that we’ll see this capability emerge simply from larger-scale training runs. This is something that will need to be carefully curated.
At Deep Science Ventures, we have been capturing data throughout our processes for over 7 years, running a process of continual optimisation which has allowed us to maintain>90% conversion from concept to real-world results even in really tough areas. Over the last few weeks, we’ve worked out how to extract different types of reasoning data from our data in such a way that it successfully replicates the decision process of our best people when confronted with similar problems. We have tested this approach across areas from advanced therapeutic design to talent identification.

Our focus now is on scaling this up to longer horizon approach generation, higher-level problems and opening up the tool to a wider user base. We are building infrastructure to achieve the following:
A goal-directed optimisation function which successfully drives towards applicability whilst co-optimising for our custom local measures around quality of the reasoning, sufficiency and necessity.
Expanding our data set of high quality applied scientific reasoning supported by Cognitive Task Analysis across our portfolio and network of over 500 applied researchers, founders, academics, industry and charity partners.
A staged process, curriculum, skills-library and benchmarks towards long-horizon multi-step reasoning search process or OODA loops knowing when to persist and when to turn back.
A delightful user experience that is not only seamless but generates cross-disciplinary interaction in a secure and non-intrusive way.
The next chapter of DSV will look at how to return this to the community, democratising high-quality applied science and allowing all boats to rise. This presents a raft of challenges across everything from UX to data security, but we are convinced it is worth the effort. If you would like to be amongst the first to test out what we’re building, you can join the waitlist at elman.ai, and if you would like to engage as a partner / funder / build with us, email me at mark - at - dsv.io